How to Become an AI Developer in 2025Как стать AI-разработчиком в 2025 годуWie man 2025 AI Developer wirdComment devenir développeur AI en 2025如何在2025年成为AI开发者
Artificial Intelligence is everywhere these days. From chatbots to self-driving cars, AI powers some of the coolest technologies we see today. If you’ve ever wondered how to break into this exciting field, you’re in the right place. In this guide, I’ll explain how you can start your journey to becoming an AI developer.
1. Learn Programming
You need to choose a programming language and learn the basics of it.
Python: It’s easy to read and write, even for beginners. (Recommended)
Java: Useful for AI in enterprise settings and large-scale systems.
C++: Often used in performance-critical AI applications like gaming and robotics.
Don’t rush into learning programming. Learn the theory step by step and reinforce it with practice. Write a few pet projects to be sure of your knowledge.
Math and statistics are very important for AI developers because they help to understand how AI works. Math is needed to create and improve models, making them work better and faster. Statistics helps to study data, find patterns, and make predictions.
Linear Algebra
Learn about vectors, matrices, and matrix operations. These are the building blocks of neural networks. For example, weights in a neural network are represented as matrices.
While not every AI developer uses calculus daily, it’s essential for understanding how models like neural networks learn through optimization (gradient descent). Focus on:
AI is built on a foundation of mathematics, but don’t let that scare you! You don’t need to know all the math to get started with AI. Step by step, you will gradually improve your skills.
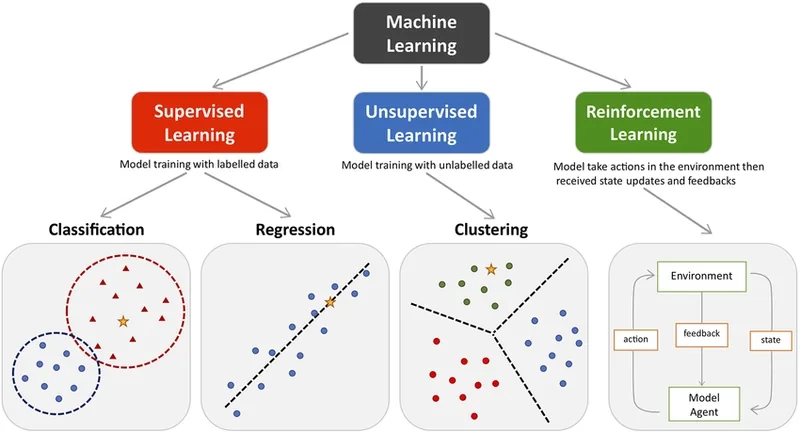
Machine learning (ML) is a branch of AI focused on enabling computers and machines to imitate the way that humans learn, to perform tasks autonomously, and to improve their performance and accuracy through experience and exposure to more data.
Types of Machine Learning
Machine learning involves showing a large volume of data to a machine so that it can learn and make predictions, find patterns, or classify data. The three machine learning types are supervised, unsupervised, and reinforcement learning.
Supervised Learning: When the model learns from labeled data (e.g., predicting house prices).
Unsupervised Learning: When the model finds patterns in unlabeled data (e.g., customer segmentation).
Reinforcement Learning: When the model learns by trial and error (e.g., training a robot to walk).
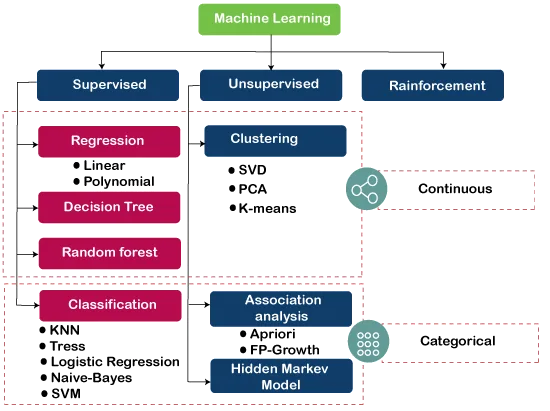
Understanding the fundamentals of key algorithms is essential for anyone entering the field of machine learning. Below are some of the foundational algorithms that form the basis for solving various machine learning problems:
Linear Regression: Predicts continuous values using linear relationships.
Decision Trees: Splits data into decision-based groups.
Support Vector Machines (SVMs): Classifies data by maximizing margins.
K-Nearest Neighbors (KNN): Predicts using closest data points.
To build AI systems, you’ll need to get comfortable with popular AI frameworks and tools. These tools simplify the process of building, training, and deploying machine learning models.
TensorFlow
Language: Primarily used with Python, other supported languages include C++, JavaScript (via TensorFlow.js), Java, Go, and Swift for specific applications.
TensorFlow is an open-source deep learning framework developed by Google. It is widely used for building and deploying machine learning and deep learning models, especially at a production level. TensorFlow offers flexibility, scalability, and a comprehensive ecosystem for end-to-end machine learning workflows.
PyTorch, developed by Facebook, is another open-source deep learning framework. It is highly favored by researchers and academics due to its flexibility and dynamic computation graph, which makes it easier to experiment and debug.
Keras is a high-level neural network API designed for fast prototyping and ease of use. It runs on top of TensorFlow and simplifies the process of building, training, and deploying neural networks. Keras is ideal for beginners and those who want to quickly implement deep learning models.
Scikit-learn is a powerful library for classical machine learning. It provides tools for data preprocessing, classification, regression, clustering, dimensionality reduction, and model evaluation. Scikit-learn is perfect for beginners and professionals working on traditional machine learning problems.
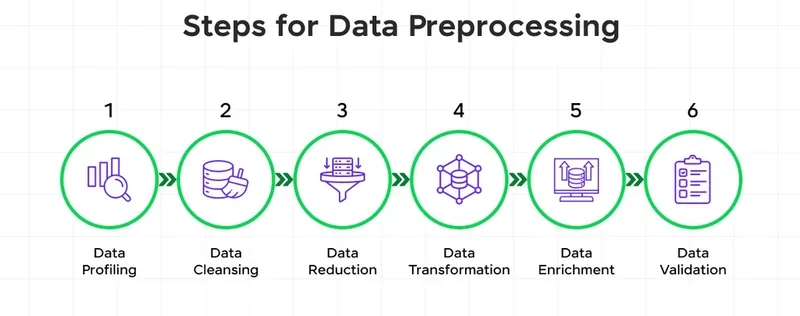
Before feeding data into an AI model, it’s crucial to clean and prepare it for analysis. Data in its raw form often contains inconsistencies, missing values, or noise. Preprocessing ensures the dataset is clean, structured, and ready for use.
EDA helps you understand the structure, patterns, and relationships within your data, which can guide your model-building process.
Using Pandas:Pandas is a powerful Python library for data manipulation and analysis. Use it to calculate statistics, filter data, and handle large datasets efficiently.
Data Visualization: Visualizing data helps uncover patterns, outliers, and relationships between variables. Libraries like Matplotlib and Seaborn allow you to create histograms, scatter plots, box plots, and heatmaps.
Uncovering Patterns: Through visualizations and statistical analysis, identify trends (e.g., seasonality in sales data) or correlations (e.g., a positive relationship between study time and grades). These insights often guide feature engineering and model selection.
When working with massive datasets that exceed the capacity of traditional tools, it’s essential to leverage Big Data frameworks.
Apache Spark:Spark is a distributed computing system designed for processing large-scale datasets. It supports machine learning, data streaming, and batch processing, making it a versatile choice for AI projects.
Hadoop:Hadoop provides a framework for distributed storage and processing of big data using the MapReduce programming model. While it is less commonly used for machine learning today, it remains a strong choice for foundational data storage.
These tools are essential for applications involving web-scale data, such as social media analysis, recommendation systems, or fraud detection, where datasets can range from terabytes to petabytes.
Искусственный интеллект сейчас повсюду. От чат-ботов до беспилотных автомобилей, AI стоит за самыми крутыми технологиями нашего времени. Если ты когда-нибудь задумывался, как попасть в эту увлекательную сферу, ты в правильном месте. В этом гиде я расскажу, как начать путь к тому, чтобы стать AI-разработчиком.
1. Изучи программирование
Нужно выбрать язык программирования и освоить его основы.
Python: Лёгкий для чтения и написания, даже для новичков. (Рекомендуется)
Java: Полезен для AI в корпоративных и крупномасштабных системах.
C++: Часто применяется в требовательных к производительности AI-приложениях, таких как игры и робототехника.
R: Если тебя интересует анализ данных и статистика.
Не торопись с изучением программирования. Осваивай теорию шаг за шагом и закрепляй её практикой. Напиши несколько пет-проектов, чтобы быть уверенным в своих знаниях.
Математика и статистика очень важны для AI-разработчиков, потому что помогают понять, как работает AI. Математика нужна, чтобы создавать и улучшать модели, делая их быстрее и точнее. Статистика помогает изучать данные, находить закономерности и делать прогнозы.
Линейная алгебра
Разберись с векторами, матрицами и матричными операциями. Это строительные блоки нейросетей. Например, веса в нейронной сети представлены как матрицы.
Не каждому AI-разработчику матанализ нужен каждый день, но без него не получится понять, как модели вроде нейросетей учатся через оптимизацию (градиентный спуск). Сосредоточься на:
AI построен на фундаменте математики, но пусть это тебя не пугает! Не нужно знать всю математику, чтобы начать с AI. Шаг за шагом ты будешь постепенно прокачивать свои навыки.
Машинное обучение (ML) — это раздел AI, посвящённый тому, чтобы компьютеры и машины могли имитировать процесс обучения человека, выполнять задачи автономно и улучшать свою производительность и точность через опыт и работу с большими объёмами данных.
Виды машинного обучения
Машинное обучение заключается в том, что машине показывают большой объём данных, чтобы она могла учиться и делать предсказания, находить закономерности или классифицировать данные. Три вида машинного обучения: с учителем, без учителя и с подкреплением.
Supervised Learning (с учителем): Модель учится на размеченных данных (например, предсказание цен на жильё).
Unsupervised Learning (без учителя): Модель находит закономерности в неразмеченных данных (например, сегментация клиентов).
Reinforcement Learning (с подкреплением): Модель учится методом проб и ошибок (например, тренировка робота ходить).
Понимание основ ключевых алгоритмов критично для всех, кто заходит в сферу машинного обучения. Ниже базовые алгоритмы, которые лежат в основе решения многих ML-задач:
Linear Regression (линейная регрессия): Предсказывает непрерывные значения через линейные зависимости.
Decision Trees (деревья решений): Разбивает данные на группы по принимаемым решениям.
Support Vector Machines (SVM, метод опорных векторов): Классифицирует данные, максимизируя зазоры.
K-Nearest Neighbors (KNN, метод ближайших соседей): Предсказывает по ближайшим точкам данных.
Чтобы строить AI-системы, нужно освоиться с популярными AI-фреймворками и инструментами. Они упрощают процесс создания, обучения и развёртывания моделей машинного обучения.
TensorFlow
Язык: В основном используется с Python, также поддерживаются C++, JavaScript (через TensorFlow.js), Java, Go и Swift для определённых задач.
TensorFlow — open-source фреймворк для глубокого обучения, разработанный Google. Широко используется для создания и деплоя моделей машинного и глубокого обучения, особенно на продакшен-уровне. TensorFlow предлагает гибкость, масштабируемость и полноценную экосистему для end-to-end ML-пайплайнов.
PyTorch, разработанный Facebook, ещё один open-source фреймворк для глубокого обучения. Его очень любят исследователи и академические сотрудники за гибкость и динамический граф вычислений, что упрощает эксперименты и дебаг.
Keras — это высокоуровневый API для нейросетей, заточенный под быстрое прототипирование и простоту использования. Работает поверх TensorFlow и упрощает процесс создания, обучения и деплоя нейросетей. Keras идеален для новичков и тех, кто хочет быстро реализовать модели глубокого обучения.
Scikit-learn — мощная библиотека для классического машинного обучения. Содержит инструменты для предобработки данных, классификации, регрессии, кластеризации, понижения размерности и оценки моделей. Scikit-learn отлично подходит и новичкам, и профи, работающим с традиционными ML-задачами.
Перед тем как подавать данные в AI-модель, важно их очистить и подготовить к анализу. Данные в сыром виде часто содержат несостыковки, пропущенные значения или шум. Предобработка обеспечивает то, что датасет чистый, структурирован и готов к использованию.
Обработка пропущенных значений.
Масштабирование и нормализация данных.
Разделение данных на обучающую и тестовую выборки.
EDA помогает понять структуру, закономерности и связи в данных, что направляет процесс построения модели.
Pandas:Pandas — мощная Python-библиотека для работы с данными и их анализа. Используй её, чтобы считать статистики, фильтровать данные и эффективно работать с большими датасетами.
Визуализация данных: Визуализация помогает увидеть закономерности, выбросы и связи между переменными. Библиотеки вроде Matplotlib и Seaborn позволяют строить гистограммы, scatter plots, box plots и heatmaps.
Поиск закономерностей: Через визуализацию и статистический анализ определяй тренды (например, сезонность в данных о продажах) или корреляции (например, положительная связь между временем на учёбу и оценками). Эти инсайты часто направляют feature engineering и выбор модели.
Когда работаешь с массивными датасетами, которые не помещаются в обычные инструменты, нужно использовать Big Data фреймворки.
Apache Spark:Spark — это распределённая вычислительная система для обработки крупномасштабных датасетов. Поддерживает машинное обучение, стриминг данных и пакетную обработку, что делает её универсальным выбором для AI-проектов.
Hadoop:Hadoop предоставляет фреймворк для распределённого хранения и обработки больших данных через модель программирования MapReduce. Сегодня для машинного обучения его используют реже, но он остаётся сильным выбором для базового хранения данных.
Эти инструменты нужны для приложений web-масштаба, таких как анализ соцсетей, рекомендательные системы или обнаружение мошенничества, где датасеты могут весить от терабайтов до петабайтов.
Künstliche Intelligenz ist heutzutage überall. Von Chatbots bis zu selbstfahrenden Autos, AI treibt einige der coolsten Technologien an, die wir heute sehen. Wenn du dich jemals gefragt hast, wie du in dieses spannende Feld einsteigen kannst, bist du hier richtig. In diesem Guide erkläre ich dir, wie du deine Reise zum AI Developer starten kannst.
1. Lerne Programmierung
Du musst eine Programmiersprache wählen und ihre Grundlagen lernen.
Python: Leicht zu lesen und zu schreiben, auch für Anfänger. (Empfohlen)
Java: Nützlich für AI in Enterprise-Umgebungen und großen Systemen.
C++: Wird häufig in performancekritischen AI-Anwendungen wie Gaming und Robotik eingesetzt.
R: Wenn du dich für Datenanalyse und Statistik interessierst.
Stürze dich nicht überstürzt ins Programmieren. Lerne die Theorie Schritt für Schritt und festige sie durch Praxis. Schreibe ein paar Pet-Projects, um sicher in deinem Wissen zu sein.
Mathematik und Statistik sind sehr wichtig für AI Developer, weil sie helfen zu verstehen, wie AI funktioniert. Mathematik ist nötig, um Modelle zu erstellen und zu verbessern, damit sie schneller und genauer arbeiten. Statistik hilft, Daten zu untersuchen, Muster zu finden und Vorhersagen zu treffen.
Lineare Algebra
Lerne Vektoren, Matrizen und Matrixoperationen. Das sind die Bausteine neuronaler Netze. Zum Beispiel werden Gewichte in einem neuronalen Netz als Matrizen dargestellt.
Nicht jeder AI Developer nutzt Analysis täglich, aber sie ist wichtig, um zu verstehen, wie Modelle wie neuronale Netze durch Optimierung (Gradient Descent) lernen. Konzentriere dich auf:
AI baut auf einem mathematischen Fundament auf, aber lass dich davon nicht abschrecken! Du musst nicht die ganze Mathematik beherrschen, um mit AI anzufangen. Schritt für Schritt baust du deine Skills auf.
Machine Learning (ML) ist ein Bereich der AI, der Computer und Maschinen befähigt, das menschliche Lernen nachzuahmen, Aufgaben autonom auszuführen und ihre Leistung und Genauigkeit durch Erfahrung und mehr Daten zu verbessern.
Arten von Machine Learning
Beim Machine Learning zeigt man einer Maschine eine große Menge an Daten, damit sie lernen, Vorhersagen treffen, Muster finden oder Daten klassifizieren kann. Die drei ML-Arten sind Supervised Learning, Unsupervised Learning und Reinforcement Learning.
Supervised Learning: Das Modell lernt aus gelabelten Daten (z.B. Vorhersage von Hauspreisen).
Unsupervised Learning: Das Modell findet Muster in nicht gelabelten Daten (z.B. Kundensegmentierung).
Reinforcement Learning: Das Modell lernt durch Versuch und Irrtum (z.B. einen Roboter laufen beibringen).
Die Grundlagen wichtiger Algorithmen zu verstehen ist essenziell für alle, die ins Machine Learning einsteigen. Unten sind einige der fundamentalen Algorithmen, die die Basis für das Lösen verschiedener ML-Probleme bilden:
Linear Regression: Sagt kontinuierliche Werte über lineare Beziehungen voraus.
Decision Trees: Teilt Daten in entscheidungsbasierte Gruppen.
Support Vector Machines (SVMs): Klassifiziert Daten durch Maximierung der Abstände.
K-Nearest Neighbors (KNN): Sagt anhand der nächsten Datenpunkte voraus.
Um AI-Systeme zu bauen, musst du dich mit populären AI-Frameworks und Tools wohlfühlen. Diese Tools vereinfachen den Prozess, Machine-Learning-Modelle zu bauen, zu trainieren und zu deployen.
TensorFlow
Sprache: Hauptsächlich mit Python verwendet, andere unterstützte Sprachen sind C++, JavaScript (via TensorFlow.js), Java, Go und Swift für bestimmte Anwendungen.
TensorFlow ist ein Open-Source-Deep-Learning-Framework, entwickelt von Google. Es wird breit eingesetzt, um Machine- und Deep-Learning-Modelle zu bauen und zu deployen, besonders auf Production-Niveau. TensorFlow bietet Flexibilität, Skalierbarkeit und ein umfassendes Ökosystem für End-to-End-ML-Workflows.
PyTorch, entwickelt von Facebook, ist ein weiteres Open-Source-Deep-Learning-Framework. Es ist bei Forschern und Akademikern sehr beliebt wegen seiner Flexibilität und seines dynamischen Computation Graph, was Experimentieren und Debuggen erleichtert.
Keras ist eine High-Level-Neural-Network-API, designt für schnelles Prototyping und einfache Nutzung. Sie läuft auf TensorFlow und vereinfacht das Bauen, Trainieren und Deployen neuronaler Netze. Keras ist ideal für Anfänger und alle, die schnell Deep-Learning-Modelle umsetzen wollen.
Scikit-learn ist eine mächtige Bibliothek für klassisches Machine Learning. Sie bietet Tools für Datenvorverarbeitung, Klassifikation, Regression, Clustering, Dimensionsreduktion und Modellbewertung. Scikit-learn ist perfekt für Anfänger und Profis, die an traditionellen ML-Problemen arbeiten.
Bevor du Daten in ein AI-Modell fütterst, ist es entscheidend, sie zu säubern und für die Analyse vorzubereiten. Daten in Rohform enthalten oft Inkonsistenzen, fehlende Werte oder Rauschen. Vorverarbeitung stellt sicher, dass der Datensatz sauber, strukturiert und einsatzbereit ist.
EDA hilft dir, die Struktur, Muster und Beziehungen in deinen Daten zu verstehen, was deinen Modellbau-Prozess leitet.
Mit Pandas:Pandas ist eine mächtige Python-Bibliothek für Datenmanipulation und -analyse. Nutze sie, um Statistiken zu berechnen, Daten zu filtern und große Datensätze effizient zu handhaben.
Datenvisualisierung: Daten zu visualisieren hilft, Muster, Ausreißer und Beziehungen zwischen Variablen aufzudecken. Bibliotheken wie Matplotlib und Seaborn erlauben es, Histogramme, Scatter Plots, Box Plots und Heatmaps zu erstellen.
Muster aufdecken: Durch Visualisierungen und statistische Analyse identifizierst du Trends (z.B. Saisonalität in Verkaufsdaten) oder Korrelationen (z.B. eine positive Beziehung zwischen Lernzeit und Noten). Diese Erkenntnisse leiten oft Feature Engineering und Modellauswahl.
Wenn du mit massiven Datensätzen arbeitest, die die Kapazität traditioneller Tools übersteigen, ist es essenziell, Big-Data-Frameworks zu nutzen.
Apache Spark:Spark ist ein verteiltes Computing-System, designt für die Verarbeitung großer Datensätze. Es unterstützt Machine Learning, Datenstreaming und Batch-Verarbeitung und ist damit eine vielseitige Wahl für AI-Projekte.
Hadoop:Hadoop bietet ein Framework für verteilte Speicherung und Verarbeitung großer Daten über das MapReduce-Programmiermodell. Heute wird es seltener für Machine Learning genutzt, bleibt aber eine starke Wahl für grundlegende Datenspeicherung.
Diese Tools sind essenziell für Anwendungen mit Web-Scale-Daten, etwa Social-Media-Analyse, Empfehlungssysteme oder Betrugserkennung, wo Datensätze von Terabytes bis Petabytes reichen können.
L’intelligence artificielle est partout aujourd’hui. Des chatbots aux voitures autonomes, l’AI alimente certaines des technologies les plus cool que nous voyons. Si tu t’es déjà demandé comment percer dans ce domaine passionnant, tu es au bon endroit. Dans ce guide, je vais t’expliquer comment commencer ton parcours pour devenir développeur AI.
1. Apprends la programmation
Il faut choisir un langage de programmation et en apprendre les bases.
Python : Facile à lire et à écrire, même pour les débutants. (Recommandé)
Java : Utile pour l’AI dans des environnements entreprise et des systèmes à grande échelle.
C++ : Souvent utilisé dans des applications AI sensibles aux performances comme le gaming et la robotique.
R : Si tu es attiré par l’analyse de données et les statistiques.
Ne te précipite pas dans l’apprentissage de la programmation. Apprends la théorie étape par étape et renforce-la avec de la pratique. Écris quelques pet projects pour être sûr de tes connaissances.
Les maths et les statistiques sont très importantes pour les développeurs AI car elles aident à comprendre comment l’AI fonctionne. Les maths sont nécessaires pour créer et améliorer les modèles, les rendre plus rapides et plus précis. Les statistiques aident à étudier les données, trouver des motifs et faire des prédictions.
Algèbre linéaire
Apprends les vecteurs, les matrices et les opérations matricielles. Ce sont les briques de base des réseaux de neurones. Par exemple, les poids dans un réseau de neurones sont représentés sous forme de matrices.
Tous les développeurs AI n’utilisent pas le calcul différentiel au quotidien, mais il est essentiel pour comprendre comment des modèles comme les réseaux de neurones apprennent via l’optimisation (gradient descent). Concentre-toi sur :
L’AI est construite sur des fondations mathématiques, mais ne te laisse pas effrayer ! Tu n’as pas besoin de connaître toutes les maths pour commencer avec l’AI. Étape par étape, tu amélioreras progressivement tes compétences.
Le Machine Learning (ML) est une branche de l’AI qui permet aux ordinateurs et aux machines d’imiter la façon dont les humains apprennent, d’exécuter des tâches de manière autonome et d’améliorer leurs performances et leur précision via l’expérience et l’exposition à plus de données.
Types de Machine Learning
Le Machine Learning consiste à montrer un grand volume de données à une machine pour qu’elle puisse apprendre et faire des prédictions, trouver des motifs ou classifier des données. Les trois types de ML sont supervised, unsupervised et reinforcement learning.
Supervised Learning : Quand le modèle apprend à partir de données étiquetées (par exemple, prédire les prix des maisons).
Unsupervised Learning : Quand le modèle trouve des motifs dans des données non étiquetées (par exemple, segmentation client).
Reinforcement Learning : Quand le modèle apprend par essais et erreurs (par exemple, entraîner un robot à marcher).
Comprendre les fondamentaux des algorithmes clés est essentiel pour quiconque entre dans le domaine du Machine Learning. Voici quelques-uns des algorithmes fondamentaux qui forment la base pour résoudre divers problèmes ML :
Linear Regression : Prédit des valeurs continues via des relations linéaires.
Decision Trees : Divise les données en groupes basés sur des décisions.
Support Vector Machines (SVM) : Classifie les données en maximisant les marges.
K-Nearest Neighbors (KNN) : Prédit en utilisant les points de données les plus proches.
Pour construire des systèmes AI, tu auras besoin d’être à l’aise avec les frameworks et outils AI populaires. Ces outils simplifient le processus de construction, d’entraînement et de déploiement de modèles ML.
TensorFlow
Langage : Principalement utilisé avec Python, d’autres langages supportés incluent C++, JavaScript (via TensorFlow.js), Java, Go et Swift pour des applications spécifiques.
TensorFlow est un framework open-source de deep learning développé par Google. Il est largement utilisé pour construire et déployer des modèles ML et de deep learning, surtout au niveau production. TensorFlow offre flexibilité, scalabilité et un écosystème complet pour des workflows ML end-to-end.
PyTorch, développé par Facebook, est un autre framework open-source de deep learning. Il est très apprécié des chercheurs et académiques pour sa flexibilité et son graphe de calcul dynamique, qui rend l’expérimentation et le debug plus faciles.
Keras est une API haut niveau pour réseaux de neurones, conçue pour un prototypage rapide et une utilisation simple. Elle tourne sur TensorFlow et simplifie le processus de construction, d’entraînement et de déploiement de réseaux de neurones. Keras est idéal pour les débutants et ceux qui veulent rapidement implémenter des modèles de deep learning.
Scikit-learn est une bibliothèque puissante pour le Machine Learning classique. Elle fournit des outils pour le prétraitement des données, la classification, la régression, le clustering, la réduction de dimensionnalité et l’évaluation de modèles. Scikit-learn est parfait pour les débutants comme pour les pros travaillant sur des problèmes ML traditionnels.
Avant de nourrir un modèle AI avec des données, il est crucial de les nettoyer et de les préparer pour l’analyse. Les données brutes contiennent souvent des incohérences, des valeurs manquantes ou du bruit. Le prétraitement garantit que le dataset est propre, structuré et prêt à l’emploi.
Gérer les valeurs manquantes.
Mettre à l’échelle et normaliser les données.
Diviser les données en sets d’entraînement et de test.
L’EDA t’aide à comprendre la structure, les motifs et les relations dans tes données, ce qui guide le processus de construction du modèle.
Avec Pandas :Pandas est une bibliothèque Python puissante pour la manipulation et l’analyse de données. Utilise-la pour calculer des statistiques, filtrer des données et gérer efficacement de gros datasets.
Visualisation de données : Visualiser les données aide à révéler des motifs, des outliers et des relations entre variables. Des bibliothèques comme Matplotlib et Seaborn permettent de créer histogrammes, scatter plots, box plots et heatmaps.
Repérer des motifs : Via la visualisation et l’analyse statistique, identifie des tendances (par exemple la saisonnalité dans des données de ventes) ou des corrélations (par exemple une relation positive entre temps d’étude et notes). Ces insights guident souvent le feature engineering et le choix du modèle.
Quand tu travailles avec des datasets massifs qui dépassent la capacité des outils traditionnels, il est essentiel d’exploiter des frameworks Big Data.
Apache Spark :Spark est un système de calcul distribué conçu pour traiter des datasets à grande échelle. Il supporte le Machine Learning, le streaming de données et le traitement par batch, ce qui en fait un choix versatile pour les projets AI.
Hadoop :Hadoop fournit un framework pour le stockage et le traitement distribués de big data via le modèle de programmation MapReduce. Aujourd’hui il est moins utilisé pour le Machine Learning, mais il reste un choix solide pour le stockage de données fondamental.
Ces outils sont essentiels pour des applications avec des données à l’échelle du web, comme l’analyse de réseaux sociaux, les systèmes de recommandation ou la détection de fraude, où les datasets peuvent peser des téraoctets à des pétaoctets.



Discussion